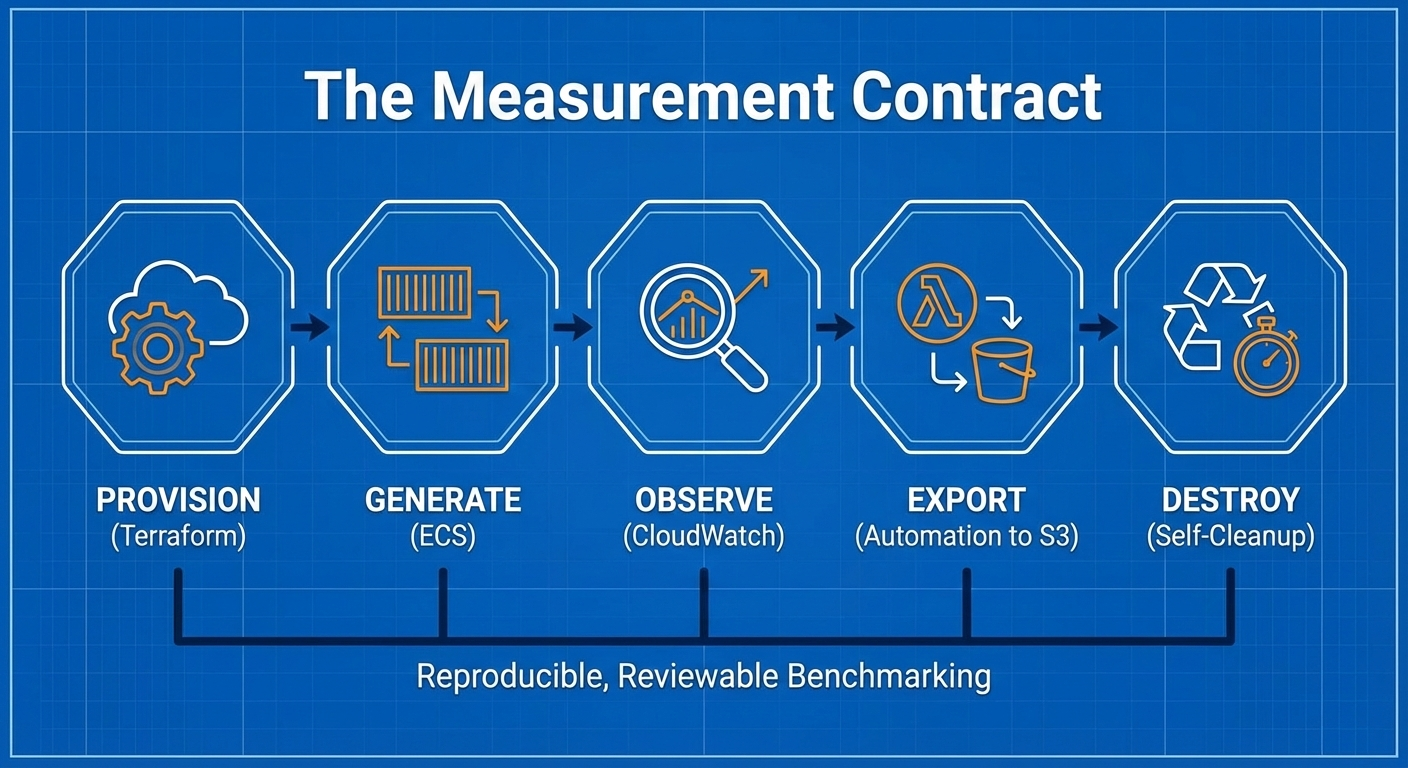
AI-Assisted Engineering: Why I Trust Verified Agent Work More Than Chat
For me, AI-assisted engineering means using Codex and other AI coding agents as engineering tools, not as magic autocomplete. The difference matters. Chat can be useful for explanation, brainstorming, and quick drafts, but infrastructure work needs something stricter: changes that can be inspected, tested, reverted, and judged against the original requirements.
My own experience is that I trust OpenAI/Codex-style agents more than Claude Code-style workflows for long-running implementation work. That is a practical tooling judgment, not a universal law. But the public DeepSWE benchmark gives useful external support for the same pattern I see in practice: OpenAI models perform very strongly on long-horizon software tasks, with better requirement completion and strong efficiency under a shared agent harness.