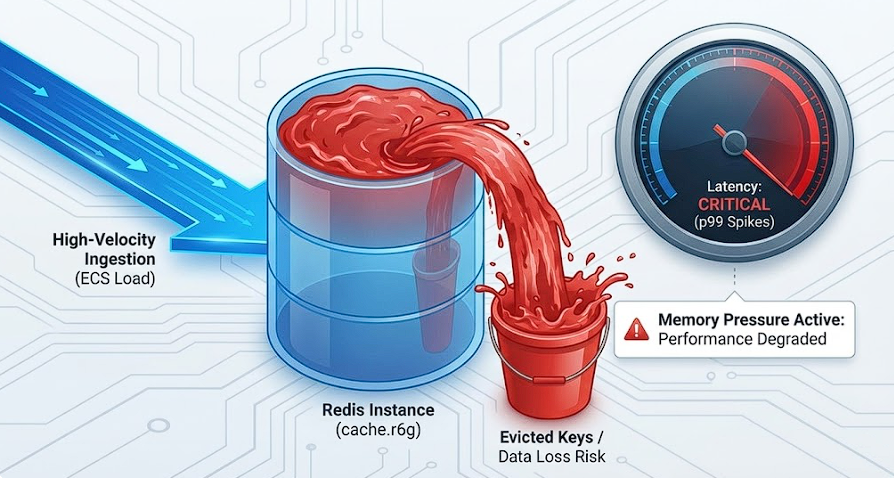
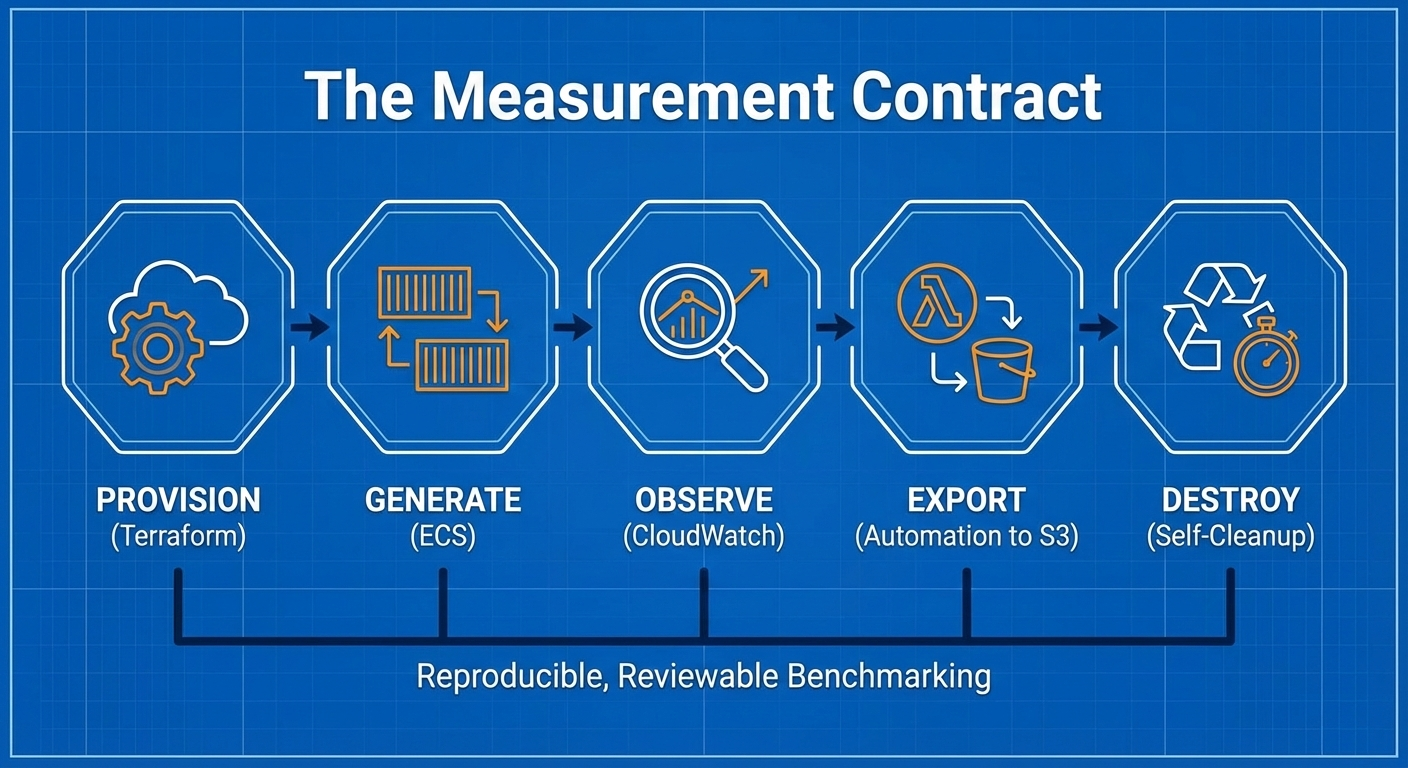
AWS ElastiCache Lab project has a hard rule: a test run is defined as one hour. That only stays true if the lab reliably shuts down on schedule. If it doesn't, I lose cost control and-more importantly for benchmarking-I risk starting the next run from a non-clean baseline.
I hit exactly that problem on an evening run.
What I observed
The run finished, but the environment was still up. Nothing looked "broken" in the usual sense: services were alive and responsive. In this lab, though, "still works" past the run boundary is a defect, because it means the lifecycle automation failed silently.